그런 점에서 PoC, 기술 데모, 그리고 전시용 홍보 영상은 목적은 다르지만 중요한 공통점을 공유합니다. 세 가지 모두, 완성된 제품이 아닌 “기술이 작동한다”는 메시지를 전하는 작업이며, 제약된 시간과 리소스 안에서 납득 가능한 형태로 결과를 구성하고 전달해야 합니다.
결국 핵심은 기능 구현 자체가 아니라, 그 기능을 어떻게 보여주고 해석되게 하느냐입니다. 실제 현장에서는 모델 정확도보다 신뢰성과 시각적 완성도가 더 중요하게 평가되는 경우도 많습니다.
이 글에서는 2025년 기준으로 진행된 몇 가지 실제 PoC와 전시용 기술 데모 사례를 바탕으로, 각 과제에서 어떤 구조를 설계하고, 어떤 방식으로 대응했는지를 정리해 보려 합니다.
먼저 PoC 검토 시 기본적으로 점검하는 항목들을 살펴본 뒤, 각 프로젝트별 흐름과 기술적 선택 과정을 차례로 다뤄보겠습니다.
기본 검토 순서
PoC 진행 전에는 다음 항목을 기준으로 기술적 사전 검토를 수행합니다:
- 모델이 있는가? (기존 모델 또는 베이스라인 존재 여부)
- 데이터셋이 있는가? (고객사 제공 여부 포함)
- 라벨링이 되어 있는가? (라벨 품질, 포맷 일치 여부)
- 테스트 영상이 있는가? (실제 운영 환경 기반의 입력)
PoC 진행 현황 (2025년 기준)
| 상태 | 고객사 | 메모 |
|---|---|---|
| PoC 완료 → 계약 |
A사 | 성능 기준 충족, 고객사 피드백 반영 중 |
| PoC 진행 중 → MOU 예정 | B사 | 기능 요구사항 재정의 중, 추가 테스트 예정 |
| 전시용 데모 및 홍보 영상 | AWS, EXPO | 기능 홍보 중심, 커스텀 적용 아님 |
이제 각 사례를 중심으로, 실제 어떤 기술적 과정을 수행했는지 정리해보겠습니다.
본 포스팅에 포함된 일부 시각 자료는 실 서비스 관련 내용이 포함되어 있어, 내부 정책 또는 보안상의 이유로 사전 고지 없이 삭제될 수 있습니다.
1. PoC 완료 사례
- 고객사: A사
- 상태:
PoC 완료, 금주 중 본 계약 조건 협의 예정계약 완료 -
비고: 해당 제품의 주 담당은 아니었지만, 일부 기능 PoC를 수행했습니다.
- 주요 업무:
- 고객 요청에 따른 Object Detection, Super Resolution 기능 PoC 수행
- 요구 클래스에 대한 데이터셋 확보 및 전처리
- 모델 구성 및 파이프라인 설계
- 시각화 영상 및 결과물 제작
- 리소스 사용량 테스트 및 GPU 견적 대응
- 기술 미팅용 보고자료 구성
1-1. Object Detection
- 사용 모델:
- Ultralytics YOLOv11
- 실험 가능성과 신뢰성을 모두 고려했고, 비교적 빠르게 튜닝 가능한 구조라는 점에서 초기 테스트에 적합하다고 판단했습니다.
-
인바운드 요청: “클래스 B 탐지 가능한가?”
→ 단 1문장 요청이었고, 응답 기한은 3일, 내부 정리는 2.5일 안에 마쳐야 했습니다. - 데이터셋 이슈:
- COCO에는 없었고, Object365에는 있었지만 데이터셋 규모가 커서 다운로드 및 전처리에 시간이 많이 소요될 것으로 판단했습니다.
- 클래스 B는 일상적인 대상이었으나, 공개된 pretrained 모델 중 해당 클래스를 포함한 모델은 확보되지 않았습니다.
- 최종적으로 Roboflow에서 유사 클래스가 포함된 여러 개의 소형 데이터셋을 수집하여 병합 구성했습니다.
- 클래스 간 중복 및 누락 여부를 수동으로 점검했고, 라벨 일관성 확보를 위해 일부 샘플은 직접 수정했습니다.
- 테스트 영상 확보 및 편집:
- 실제로 가장 어려운 단계는 적절한 테스트 영상을 확보하는 것이었습니다.
- 유튜브 등에서 클래스 B가 명확히 등장하는 장면을 선별하고,
고객 요구조건, 탐지 난이도, 실적용 가능성을 모두 고려해 편집했습니다. - 영상은 탐지가 잘 되도록 조명, 프레임 구성, 해상도 등을 다각도로 조정했습니다.
- 반복 작업:
- 동일 테스트 영상에 대해 다양한 모델 파라미터를 변경하며 반복 실험을 수행했습니다.
- 그 과정에서 영상 재편집 → 데이터셋 보완 → 모델 재학습 사이클을 4~5회 반복하며,
탐지 정확도와 시각적 신뢰도를 모두 만족시키도록 성능을 안정화했습니다.
- 산출물 구성:
- 최종 결과물은 다음 세 가지로 구성했습니다.
- “됩니다.”라는 결론 문장
- “됩니다.”의 근거가 되는 시각화 영상
- 테스트 환경에서의 리소스 사용 정보 요약본
- 시각화 영상은 테스트 영상 위에 탐지 결과를 오버레이해 생성했고,
Object Detection 기능이 실환경에서도 충분히 유효하다는 점을 직관적으로 전달할 수 있도록 구성했습니다.
- 최종 결과물은 다음 세 가지로 구성했습니다.
1-2. Super Resolution (화질 개선)
- 사용 모델 및 구성:
- Real-ESRGAN (Super Resolution)
- GFPGAN (Face Enhancement)
→ 기능적으로 구분되며 리소스 특성이 다릅니다.
- 배경 및 모델 서치:
- 해당 주제는 대학원 시절 직접 다룬 경험이 있어,
PoC 시점에서 모델 서치 및 구조 이해에 소요되는 시간을 절약할 수 있었습니다. - 검토 초기부터 Real-ESRGAN + GFPGAN 조합으로 방향을 정하고 테스트에 집중했습니다.
- 해당 주제는 대학원 시절 직접 다룬 경험이 있어,
- 작업 흐름:
- 화질 개선 효과를 직관적으로 비교하기 위해 원본 해상도를 인위적으로 낮춘 뒤
전후 영상을 구성하고, 출력 퀄리티와 인식 적합성을 함께 평가했습니다. - upscale 비율에 따른 성능 차이, 영상 길이에 따른 처리 시간,
단독 사용 대비 병합 사용 시의 리소스 소모를 비교했습니다. - 또한, 고객사 측에서 GPU 견적 문의가 있었기 때문에
Object Detection과 달리 리소스 사용량에 대한 정량 테스트가 특히 중요했습니다.
- 화질 개선 효과를 직관적으로 비교하기 위해 원본 해상도를 인위적으로 낮춘 뒤
- 특이사항:
- 일반적인 단일 이미지 추론에서는 비교적 가볍지만,
고해상도 영상의 프레임 전체를 연속적으로 생성하거나,
두 모델을 동시에 사용할 경우 GPU 메모리 사용량과 latency가 급격히 증가합니다. - 특히 GAN 계열 모델은 inference 상황에서도 frame 단위 병렬 처리가 제대로 되지 않으면
OOM 이슈가 발생할 수 있으므로, 분석엔진 인터페이스 설계 시
다른 모델들과의 자원 분배 및 스케줄링 조정이 필수적입니다.
- 일반적인 단일 이미지 추론에서는 비교적 가볍지만,
- 산출물 구성:
- 최종 결과물은 다음 세 가지로 구성했습니다.
- “됩니다.”라는 결론 문장
- “됩니다.”의 근거가 되는 전후 비교 영상
- 영상 해상도, 길이, 적용 모델별 리소스 사용 요약 리포트
- 시각화 영상은 화질 저하 전/후를 프레임 단위로 비교할 수 있도록 구성했고,
실제 사용 환경에서의 개선 효과를 직관적으로 보여주는 데 초점을 맞췄습니다.
- 최종 결과물은 다음 세 가지로 구성했습니다.
시스템 구성
계약 체결이 완료됨에 따라,
협약 기관의 보안 정책에 의거하여 기존에 공개되었던 일부 내용을 비공개 처리하였습니다.
A사 PoC 과제별 기본 검토 항목
| 항목 번호 | 검토 항목 | Object Detection | Super Resolution |
|---|---|---|---|
| 1 | 모델이 있는가? | X (직접 학습) | O (pretrained) |
| 2 | 데이터셋이 있는가? | X (직접 구축) | X (불필요) |
| 3 | 라벨링이 되어 있는가? | O (Roboflow 다운로드) | X (불필요) |
| 4 | 테스트 영상이 있는가? | X (직접 생성) | X (직접 생성) |
PoC 구성 비교
| 항목 | Object Detection | Super Resolution |
|---|---|---|
| 테스트 환경 구성 난이도 | 영상 수집 및 조건 맞춤 편집 중심 | 해상도/길이 조절 중심 |
| 리소스 측정 중요도 | 중간 | 매우 높음 (GPU 견적과 연동됨) |
정리
A사의 Object Detection과 Super Resolution PoC는 모두 사전 모델과 완성된 데이터 없이 시작된 과제로,
Applied AI Engineer가 데이터 확보부터 테스트셋 구성까지 전 과정을 직접 수행한 실무 사례입니다.
(단, 이 과정은 시스템 관점의 End-to-End가 아닌, 모델 파이프라인에 한정된 End-to-End 구조였습니다.)
-
Object Detection은 분석엔진 인터페이스가 이미 개발되어 있던 상황에서,
모델 성능 검증과 데이터 파이프라인 설계에 집중한 모델 관점의 End-to-End형 PoC였습니다.
(외부 공개 데이터를 재가공해 학습하고, 테스트셋 설계 및 시각화까지 직접 수행) -
Super Resolution은 학습 없이 pretrained 모델을 활용했지만,
영상 테스트셋은 직접 생성 및 편집하여 화질 향상 효과와 리소스 사용량을 실증적으로 검증했습니다.
→ 두 과제 모두 기술 검증은 물론, 리소스 요구 수준과 운영 가능성까지 평가한 실무 기반의 PoC로 구성되었습니다.
개인적으로 AI Engineer라면 최소한 모델 단위 End-to-End 구성 역량은 필수라고 생각합니다.
데이터 수집, 정제, 라벨링을 포함한 전처리 단계에 대한 이해와 경험이 부족하면,
PoC 이후 실제 제품화 단계에서 리더나 고객사의 피드백에 적절히 대응하기 어려워질 수 있습니다.
특히 문제의 원인이 데이터에 있을 때, 모델이나 시스템만 조정해서는 해결되지 않는 경우가 많기 때문입니다.
PoC 단계에서 데이터 흐름 전반을 직접 점검하고 설계해보는 경험은
AI Engineer의 실무 역량을 근본적으로 끌어올리는 기반이 됩니다.
2. PoC 진행 중 → MOU 예정
- 고객사: B사
- 상태: PoC 진행 중, MOU 체결 예정
- 적용 방식: 영상 업로드 후 자동 분석
- 비고: 최초 해외 레퍼런스로, 실시간 영상 스트리밍 기반이 아닌 동영상 업로드 후 분석하는 후처리 구조
- 주요 담당 업무:
- Head Detection 모델 검증 및 탐지 한계 분석
- 카운팅 로직 설계 및 구조 전환 (기준선 → Polygon + Hysteresis 기반)
- 카운팅 후처리 로직 구현 및 안정성 검토
- 분석엔진 내부 인터페이스 및 시각화 연동 구현
- 시연용 결과물 및 데모 영상 제작
- 기준선/Zone 정의 가이드 제공 및 카메라 설치 위치 조율
- 고객사 PoC 현장에 적용된 On-Premise 분석엔진 운영 및 서버 이슈 대응
2-1. Object Counting Logic 설계 및 구조 전환
기반 구조: Detection + Tracking 결합
-
본 PoC는 Object Detection과 Object Tracking을 결합한 후처리 구조로, 매 프레임 객체를 감지한 뒤, track_id 기반 이동 경로를 활용하여 객체의 진입/이탈 상태 변화를 판단하고 중복 없이 카운팅합니다.
-
트래킹 알고리즘은 ByteTrack, OC-SORT, BoT-SORT를 검토하였으며, 속도, ID 일관성, 실환경 적합성 기준으로 최종적으로 ByteTrack을 적용하였습니다.
초기 구조: 기준선 기반 Cross Product 방식
-
PoC 초기 환경은 지하철 개찰구와 유사한 수평 통행 구조로, 객체가 정해진 방향으로만 이동하는 조건이었습니다. 이 구조에서는 기준선을 수평으로 설정하고, 객체 중심 좌표가 선을 어느 방향으로 교차하는지를 cross product로 계산하여 방향을 판별했습니다.
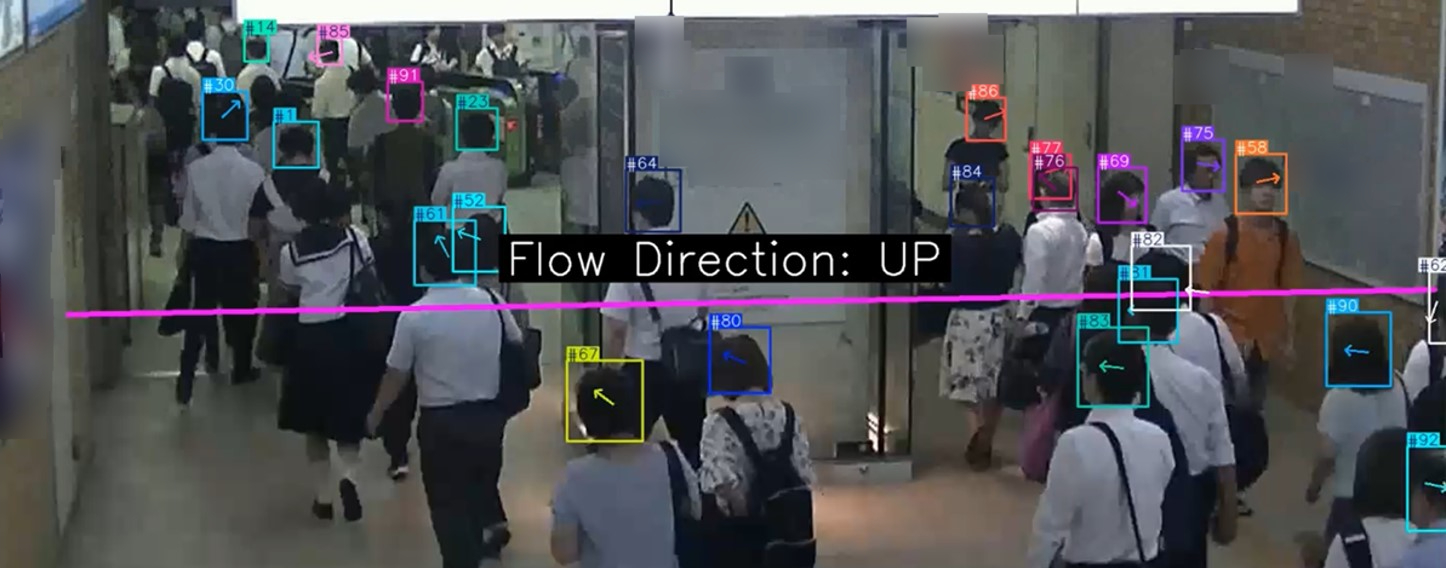
-
동일 객체가 중복 카운트되지 않도록
track_id기반으로 기록하여 관리했습니다.
cross_product = movement_vec[0] * line_vec[1] - movement_vec[1] * line_vec[0]
if cross_product > 0:
direction = "IN"
elif cross_product < 0:
direction = "OUT"
기준선 기반 구조의 전제 조건
- 기준선은 수평 또는 수직에 가까운 직선일 것
- 객체의 Bbox 크기는 프레임 간에 큰 변동이 없어야 할 것 → 위 조건이 충족되지 않으면 방향 오판단, 중복 또는 누락 카운팅이 발생할 수 있습니다.
2-2. 구조 전환: Hysteresis 기반 Polygon Zone 방식
구조 전환 배경
-
실제 분석 대상은 지하철 계단 환경이었으며, 다음과 같은 문제점이 있었습니다:
- 객체가 계단을 오르내리며 기준선을 반복적으로 교차
- Head detection만으로는 기준선 교차 시점을 정확히 포착하기 어려움
- GT 라벨 기준은 Zone 진입 여부였지만, 기준선 기반 로직과 일치하지 않음
Hysteresis란?
Hysteresis(이력현상)는 객체가 경계 근처에 있다고 해서 바로 상태를 전환하지 않고, 일정 조건이 충족될 때에만 상태 전이를 허용하는 방식입니다. 이를 통해 짧은 시간 내 진입/이탈 반복이나 오탐을 방지할 수 있습니다.
Zone 기반 로직 설계
- 아래는 계단에서 Polygon 기반 영역(Hysteresis 적용 포함)을 시각화한 이미지입니다.

현재는 모자나 대머리와 같이 특징이 뚜렷하지 않은 객체에 대한 탐지가 어려운 상황이며,
고객사와 MOU 체결 이후, Head Detection 모델 파인튜닝을 통해 개선할 예정입니다.
- 계단 상단을 Polygon 영역으로 정의하고,
내부(inner), 외부(outer), 경계 buffer 구간을 설정해 객체의 위치 상태를 판단합니다. - 또한, 이전 상태와의 비교 및 최소 프레임 간격 조건을 함께 고려해 카운팅을 수행합니다.
if inner_zone.contains(object_point):
new_state = True
elif not outer_zone.contains(object_point):
new_state = False
else:
new_state = track_data["inside"] if track_data["inside"] is not None else counting_zone.contains(object_point)
- 프레임 간격 조건:
if new_state != track_data["inside"] and (frame_index - track_data["last_counted_frame"] >= frame_threshold):
...
방향 보정 (필요 시)
- Hysteresis 기반 구조는 객체의 존재 여부 판단에는 강점이 있으나, 이동 방향 자체는 제공하지 않기 때문에 필요 시 y축 좌표 변화량을 기준으로 방향을 보정합니다:
y_drift = track_data["points"][-1][1] - track_data["points"][-5][1]
direction = "DOWN" if y_drift > 0 else "UP"
이 방식은 수직 이동이 명확한 계단 환경에서 특히 유효하며, “내려온 사람만 카운트”와 같은 조건 필터링에도 적합합니다.
2-3. 시각화 및 결과물 구성
- Bounding Box 및 Track ID 시각화
- in1, out2 등 실시간 라벨 표시
- IN/OUT 오버레이 (
IN: 7 OUT: 5) - 최종 카운팅 결과 요약본 (
.json)
B사 PoC 과제별 기본 검토 항목 (Object Detection 기준)
| 항목 번호 | 검토 항목 | MOU 전 상태 | MOU 후 예상 상태 |
|---|---|---|---|
| 1 | 모델이 있는가? | △ (연구소에서 TensorRT 엔진 전달받음) | O (모자, 대머리 등 파인튜닝 예정) |
| 2 | 데이터셋이 있는가? | △ (일부 확보됨) | △ (전달 가능성 있음 또는 별도 구축 필요) |
| 3 | 라벨링이 되어 있는가? | △ (일부 확보됨) | △ (라벨 정합성 검토 및 보완 필요) |
| 4 | 테스트 영상이 있는가? | △ (일부 확보됨) | O (대량 테스트 영상 전달 예정) |
정리
본 과제는 지하철 유동인구 분석을 위한 영상 기반 카운팅 PoC로, 시간대에 따라 프레임 내 객체(Bbox) 수가 수백 개 이상 발생하는 환경입니다. 이에 따라 트래킹 및 후처리 병목이 발생할 수 있으며, 성능 최적화 및 리소스 개선은 MOU 체결 이후 단계에서 추진될 예정입니다.
-
초기에 기준선 기반 cross product 로직을 적용했으나, 계단 환경에서는 객체의 반복 교차, ID 변경, 기준 불일치 등의 문제가 발생했습니다.
-
이를 보완하기 위해 Polygon Zone + Hysteresis 기반 구조로 전환하여 상태 유지, 프레임 간 조건, 중복 방지 조건 등을 통합한 더 안정적인 카운팅 구조를 구성했습니다.
-
트래킹 알고리즘은 ByteTrack, OC-SORT, BoT-SORT를 비교 실험하였으며, ByteTrack이 속도와 ID 일관성 면에서 가장 적합하여 최종적으로 적용되었습니다.
객체를 탐지한 뒤, 어떻게 “추적하고 판단할 것인지”에 따라 전체 시스템의 신뢰도와 결과 정확도가 크게 달라진다는 점을 보여준 프로젝트였습니다.
3. 전시용 데모 및 홍보 영상
- 대상: 클라우드 행사(AWS), 산업 전시회(EXPO) 등
- 목적: 기술력, 브랜드 이미지 강조
주요 업무
- 시연용 영상에 최적화된 모델 결과 구성
- 박스, 색상, 텍스트 등 시각 요소 강조
- 프레임 수, 타이밍 등 영상 편집용 포맷 대응
- 마케팅/기획팀과 협업하며 연출 반복
특징
- 실제 성능보다 “보여지는 느낌”이 더 중요합니다.
- 기술적 난이도는 낮지만 손이 가장 많이 가는 작업입니다.
- 모델 설계부터 시각화까지 흐름을 스스로 구성한
Full-cycle Model-level End-to-End 사례입니다.
(이 또한 시스템 단위의 End-to-End는 아닙니다.)
3-1. AWS
- 주제 조건
- 제조업, 스마트팩토리 관련
- 카운팅 기능 포함
-
ShutterStock에서 후보 영상을 탐색하고, 상사의 컨펌을 받아 영상 구매 후 연구소에 전달하였습니다.
연구소는 라벨링 후 Detection 모델 학습을, 저는 시각화만 담당하기로 되어 있었습니다. -
그러나 의장님의 피드백:
“bbox 너무 식상해, 색깔도 너무 안 예쁘고.”
→ 해당 피드백으로 기존 박스 기반 구조는 폐기되었고, Segmentation 방식으로 전환되었습니다.
이후 라벨링부터 모델 구조 변경, 시각화까지 모두 단독으로 진행하게 되었습니다. -
이처럼 PoC 단계에서는 클래스 정의와 구조 자체가 유동적이기 때문에,
라벨링을 외주화하기보다는 AI Engineer가 직접 손을 대는 경우가 많습니다.→ 이 사례 역시, 간단한 요청에서 출발했지만 전체 라벨 구조와 모델 파이프라인이 바뀐 대표적인 경우입니다.
-
마케팅팀 요구사항을 반영하며 시각화 수정이 반복되었고,
해당 영상은 행사 발표 자료 및 현장 반복 재생용으로 사용되었습니다. - 추가 이슈
- 기본 설계는 On-Premise 환경을 기준으로 되어 있었으나,
행사 목적에 맞춰 클라우드 기반 제품으로의 확장 가능성을 보여주기 위해
분석엔진과 웹 인터페이스를 AWS 환경에 임시 배포해 시연을 구성하였습니다. - 추론 속도를 높이고 GPU 사용률을 낮추기 위해 TensorRT 변환을 적용하여,
클라우드 환경에서의 리소스 비용 부담도 일부 완화할 수 있었습니다. - 웹 시연을 대비해 사내 CCTV를 활용하여 보호구 착용 후 데모용 시연 영상을
직접 촬영 및 편집하였습니다. - AI Backend 담당자가 예비군 훈련으로 부재하여
(지금 생각해보면 고의성이 의심됩니다.)
분석엔진 백업 운영을 본사에서 직접 대응하게 되었습니다.
- 기본 설계는 On-Premise 환경을 기준으로 되어 있었으나,
3-2. AI EXPO 전시용 영상
- 주제 조건:
- 제조업, 스마트팩토리 관련
- 카운팅 기능 포함
- 가능하다면 로보틱스, 자율주행 관련 포함
- 전체 구성: 총 3개 영상, 약 1개월간 준비
- 작업 흐름:
ShutterStock 영상 후보 탐색 → 상사 및 팀원과 검토 후 구매 → 전처리
→ Segmentation 라벨링 (1000장 이상, 폴리곤 기준)
→ 오버피팅 학습 → 시각화 결과 제작 → 무한 피드백 반영 → 재학습 반복 - 작업 특이사항:
- ShutterStock 영상 후보를 고르는 과정부터 많은 시간이 소요되었으며,
영상의 구도, 대상 객체, 연출 가능성 등을 고려해 상사와 팀원까지 모두 참여한 의사결정이 필요했습니다. - Segmentation 라벨링은 Roboflow에서 제공하는 세미 오토 라벨링을 도입해봤으나,
완전 자동은 불가능했고 후처리와 수작업 보정이 많아 실제 피로도는 수동과 큰 차이가 없었습니다.
- 영상별 요구사항이 달라 3개의 모델을 별도 구성해야 했으며,
오버피팅 기반 재학습만 각기 3~4회 이상 반복하였습니다.
이 과정에서 클래스 정의가 바뀌거나, 데이터셋이 수시로 추가됩니다.
-
그럼에도 오탐이 발생해 시각화 코드에서 특정 ROI 구간을 지정하고,
해당 영역에는 결과를 표시하지 않도록 처리해 영상 완성도를 맞추기도 했습니다.# Define restricted zones (x1, y1, x2, y2) restricted_zones = [ (678, 0, 896, 81), (1044, 199, 1191, 273), (1466, 873, 1583, 983) ] def is_inside_zone(box, zones): bx1, by1, bx2, by2 = box for zone in zones: zx1, zy1, zx2, zy2 = zone # Check if the box is completely inside the zone if zx1 <= bx1 and zy1 <= by1 and zx2 >= bx2 and zy2 >= by2: return True return False # For segmentation results for i, mask in enumerate(masks): # Get mask bounding box rows = np.any(mask, axis=1) cols = np.any(mask, axis=0) if np.any(rows) and np.any(cols): y1, y2 = np.where(rows)[0][[0, -1]] x1, x2 = np.where(cols)[0][[0, -1]] # Skip drawing mask if inside restricted zone if is_inside_zone((x1, y1, x2, y2), restricted_zones): continue # Mask drawing code... - 협업 없이 전체 과정을 단독 수행하였으며,
특히 1번 영상은 내부 구성원들로부터 완성도에 대한 긍정적인 평가를 받았고, 최종적으로 행사 주요 시연 영상으로 지정되었습니다.
- ShutterStock 영상 후보를 고르는 과정부터 많은 시간이 소요되었으며,
전시용 데모 및 홍보 영상 검토 항목
| 항목 번호 | 검토 항목 | AWS 데모 (웹 시연용) | AWS 홍보영상 | AI EXPO 홍보영상 |
|---|---|---|---|---|
| 1 | 모델이 있는가? | O (모델 보유, TRT 변환 필요) | X (직접 학습) | X (직접 학습) |
| 2 | 데이터셋이 있는가? | O (보호구 클래스별 기존 데이터) | X (주제 기반 수집 및 구성) | X (주제 기반 수집 및 구성) |
| 3 | 라벨링이 되어 있는가? | O (BBox 기반, 일부 백업 참여) | X (Segmentation 직접 수행) | X (Segmentation 직접 수행) |
| 4 | 테스트 영상이 있는가? | X (직접 보호구 착용 후 촬영) | O (학습 영상 = 테스트 영상) | O (학습 영상 = 테스트 영상) |
세부 구성 비교 요약표
| 항목 | AWS 데모 (웹 시연용) | AWS 홍보영상 | AI EXPO 홍보영상 |
|---|---|---|---|
| 목적 | 분석엔진 시연 (웹/클라우드 기반) | 브랜드 이미지 강조용 시각화 영상 제작 | 산업 전시회 전용 시각화 영상 제작 (총 3편) |
| 모델 | 보유 (YOLO 기반, TRT 변환 필요) | 미보유 → Segmentation 직접 학습 | 미보유 → Segmentation 직접 학습 |
| 데이터셋 | 기존 보호구 클래스 중심 | 주제 기반으로 직접 수집 및 구성 | 주제 기반으로 직접 수집 및 구성 |
| 라벨링 방식 | 기존 BBox (일부 백업 참여) | Bbox 일부, Segmentation 라벨링 직접 수행 | Segmentation 라벨링 직접 수행 (1000장 이상) |
| 테스트 영상 구성 | 보호구 착용 후 직접 촬영 | 학습 영상 = 테스트 영상 (오버피팅 기반) | 학습 영상 = 테스트 영상 (오버피팅 기반) |
| 시각화 반복 | 낮음 | 높음 (내부 피드백 반복 적용) | 매우 높음 (3편 각각 반복 피드백, ROI 예외 처리 포함) |
| 협업 여부 | 분석엔진 구축 포함 (AI Backend 협업) | Detection 연구소 협업, Segmentation 단독 전환 | 단독 수행 |
홍보 영상, 왜 가장 고생스러울까?
기능보다 시각 연출이 우선됨
- 기능 구현 여부보다 시각적 인상과 연출이 우선 기준이 됩니다.
- 수 초 단위 영상에서도 컬러, 타이밍, 박스 위치 등 세부 요소에 대한 반복 요청이 발생합니다.
- 일부 피드백은 전체 라벨 구조 변경이나 시각화 방식 변경까지 유도합니다.
- 제작 중 추가 요청이 들어오는 경우도 잦으며, 일정 변경 없이 요구사항이 누적되는 경향이 있습니다.
비전문가 중심의 피드백 루프
- 기술적 구현 난이도와 무관하게 결과에 대한 주관적 평가가 이루어집니다.
- 예시 피드백:
- “더 극적으로 표현할 수 없나요?”
- “왜 이 장면에서는 객체를 인식하지 못하나요?”
- 감성적 피드백에 따라 반복적인 수정이 발생하며, 기준이 명확하지 않은 경우가 많습니다.
반복되는 후속 요청과 품질 기준의 유동성
- 영상 압축, 배속 조절, 자막 위치, 색상 조정 등 세부 항목에 대한 수정이 반복됩니다.
- 실제 모델 성능보다는 시각적 일관성과 만족도를 기준으로 품질이 판단되는 구조입니다.
주요 피드백 사례:
- “이 부분은 투명하게 해달라” → “더 투명하게 해달라” → “이건 너무 투명하다”
- “이 클래스는 이 색상이 더 나아 보인다”
- “글자가 너무 크다 / 글씨체가 어울리지 않는다”
- “카운팅 숫자가 가려진다 / 위치를 바꿔달라”
- “배속 / 슬로우 효과 추가”, “좌우에 영상 클립 병합”
- “고화질로 변환 가능 여부”, “TV 재생을 고려해 영상 해상도 조정 필요”
저는 꾸미기에 소질이 없기 때문에, 초반에 시각화 요청을 구체적으로 말해주지 않으면
무한 피드백 지옥에 빠지게 됩니다.
4. 2025 AI EXPO 후기
2025년 AI EXPO에 자사 제품의 기술 담당자로 참가했습니다. 총 3일간 진행된 행사 중 첫날 부스 운영과 현장 대응을 맡았고, 제가 제작한 3종 홍보 영상과 AWS 데모용 웹 시연 영상(실제 보호구 착용 장면 포함)이 전시 부스 내에서 반복 재생되는 형태로 운영되었습니다.
첫날에 배정된 덕분에, 참관객들의 질의응답을 가장 많이 대응할 수 있었고 현장에서 다양한 피드백을 직접 들을 수 있었습니다. 유튜브 라이브 카메라를 피해 다니려 노력했지만 몇 차례 노출되었고, 보도자료 사진에도 제 모습이 실리게 되었습니다.
다른 부스들도 둘러보고 싶었지만, 여유 시간이 모자라 두 군데 정도만 짧게 방문할 수 있었습니다. 이런 전시 행사는 바로 성과로 이어지기보다는, 수개월~1년 뒤에 실질적인 문의로 연결되는 경우가 많습니다. 실제로 이번 EXPO 이후, 벌써 2건의 기업 문의가 유입되기도 했습니다.
저는 공학 석사이자 경영학 학사 출신으로,
기술과 제품 사이의 균형을 항상 고민합니다.
“어떻게 만들어야 잘 팔릴까?”는 제가 AI Engineer로서 꾸준히 갖고 있는 질문이며,
결국 기술은 제품화되고, 선택되어야 살아남는다는 점을 늘 염두에 두고 있습니다.
이번 EXPO 현장에서도 모델 성능보다는 실사용 환경에서의 경험을 중심으로 설명했습니다. 영상 분석 모델은 이미 일정 수준의 정확도에 도달해 있기 때문에, 현장에서는 알람 피로도, 사용자 맞춤 필터링, 도입 이후의 관리 용이성 등이 더 중요한 평가 요소로 작용합니다.
실제로 저는 다음과 같은 점을 강조했습니다:
- UI상에서 채널별 / 관리자별 / 모델별 / 클래스별로 세분화된 필터링 가능
- 알람 빈도나 대상 조건을 현장 환경에 맞춰 유연하게 조정 가능
- 기존 고객사 사례에서 보호구 탐지 → 물류 영역으로 확장 적용이 논의되고 있음
기능 설명을 넘어서, 기술의 유연성과 확장 가능성까지 함께 전달하는 데 중점을 두었습니다. 이는 곧 제품 설계 측면에서 실질적인 경쟁력이 무엇인지, 현장의 언어로 풀어내는 작업이기도 했습니다
이번 EXPO는 제품의 정식 런칭 이후 첫 외부 공개 무대였습니다. 내부적으로는 이전부터 납품 경험이 있었지만, 공식적인 전시는 이번이 처음이었기에 제게도 기술적 설명 이상의 의미가 있었습니다.
외국인 방문객의 대응도 중요한 경험이었습니다. 준비되지 않은 상태에서의 즉흥적인 영어 설명은 다소 어려웠고, 다음 행사부터는 기술 포인트를 영어로도 매끄럽게 전달할 수 있도록 사전 준비가 필요하겠다는 점을 느꼈습니다.
돌이켜보면, 첫날에 배정된 것도 어쩌면 의도된 선택이었는지 모릅니다.
팀 내에서 입사 순서상 막내였기 때문이죠.
(물론 나이로는 막내가 아닙니다.)
당시에는 몰랐지만, 시간이 지나고 나니 알게 되는 것들이 있습니다.
그래서 기록이 중요하다는 걸 다시 한번 느꼈고, 지금이라도 남길 수 있어 다행입니다.
마무리
PoC는 늘 시간과 리소스가 빠듯한 상태에서 시작됩니다. 정해진 모델도, 준비된 데이터셋도 없이, 어떻게든 가능성을 증명해야 하는 과제가 남겨집니다. 그래서 때로는 모델보다 데이터에 더 많은 시간을 쓰게 되고, 설계보다 시각화에 더 많은 공을 들이게 됩니다. 그 과정은 외롭고 반복적이며, 방향이 맞는지 확신할 수 없는 순간도 많습니다.
그래도 끝까지 손을 놓지 않으면 “여기까지는 도달할 수 있다”는 기준선은 남길 수 있습니다.
누군가에게 보여주기 위해서든, 스스로 확인하기 위해서든 말입니다.
기술은 결국 보여지는 방식으로 이해되고, 설득은 수치보다 맥락과 타이밍에 좌우되는 경우가 많습니다.
전시 영상은 더 명확한 목적과 방향성을 갖고 제작됩니다. 기능 구현보다는 메시지 전달과 연출, 보여주는 방식의 완성도가 핵심입니다. 또한 예측 가능성이 높은 영역이기도 합니다. 결과를 어느 정도 예상하며 만들 수 있고, 요구사항에 맞춰 시각적으로 조정해 나가는 과정에 집중할 수 있습니다.
이번 전시도 그런 흐름으로 마무리되었습니다. 제가 제작한 영상이 부스에서 재생됐고, 현장에서 여러 방문자들 앞에서 제품 설명을 이어갔습니다. 피곤했지만, 좋은 질문도 몇 가지 오갔습니다.
그리고 다시 PoC 자리로 돌아왔습니다. 이 모든 과정을 마쳤어도 정식 계약으로 이어질지는 미지수입니다. 결과가 확정되지 않으면 남는 건 쓰임을 다한 산출물뿐이며, 그 앞에서 한동안 생각이 머뭅니다. 특히 처음부터 끝까지 혼자 감당한 프로젝트일수록 더 깊게 남습니다.
어떤 프로젝트는 결과로 이어지고, 어떤 프로젝트는 마음에 남은 채 조용히 사라질지도 모릅니다. 그 둘을 지금은 구분할 수 없지만, 제가 할 수 있는 일은 모든 과정을 끝까지 겪어내는 것입니다.
그리고 언젠가 그 경험이 다음 선택의 기준이 될 수 있기를 바랍니다.
]]>